MoE 梳理
基础概念
什么是 MoE?
MoE(Mixture of Experts,专家混合)是一种组件级的模型设计思想。它将 Transformer 架构中的稠密前馈网络(Dense Feed Forward Network, FFN,通常由线性层、激活函数和再线性层组成)替换为稀疏选择的专家前馈层(Sparse Switch FFN Layer)。 在这种结构下,模型在每次前向计算时只激活部分专家,从而实现稀疏计算。
为什么使用 MoE?
MoE 能够在保持与传统稠密模型相同参数规模的前提下,通过仅激活少量专家参与推理,大幅降低实际计算量,从而用更少的计算量得到了模型规模的增益效果。 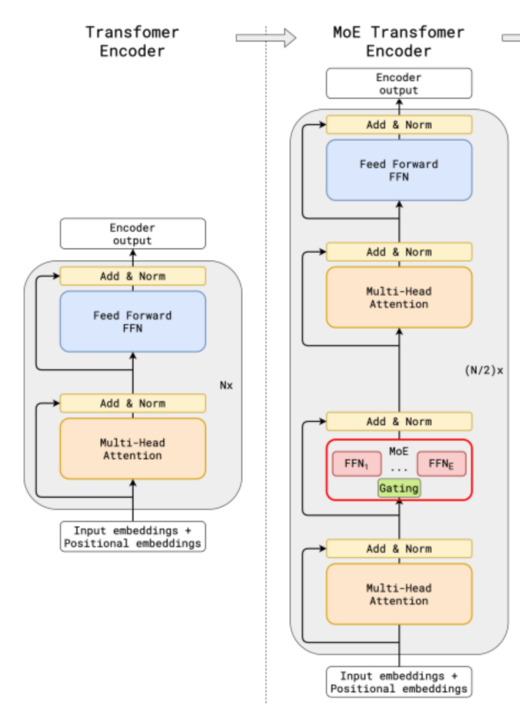
MoE 的具体过程是怎么样的?

负载均衡
负载不均衡是什么样的,会有什么后果?
如果负载不均衡时,则少部分专家会频繁被激活,部分专家会闲置,这时候有 2 个问题:
- 模型性能退化成了少参数的稠密模型,模型性能下降。
- 部分专家长期闲置,导致显卡资源浪费。
为此,MoE 架构通常会有 2 个设置来增强负载均衡:
- 限制专家容量:限制一个专家能处理的 token 数量,多的 token 就丢弃,或者用残差的方式传递给下一层。
- 使用负载均衡辅助损失项(LBL),约束每个专家被选择的概率接近。
什么是负载均衡辅助损失项?

这里有两个细节: 1.为什么最后系数包含 N? 因为理想情况下每个专家被选到的概率是
, 那么 和 的理想情况就应该都是 ,则 ,故而乘上 N 可以使得损失不会随着专家数量变化。 此外,理想情况为什么都是 ,也可以从数学角度证明,见 https://zhuanlan.zhihu.com/p/18062746529
- 为什么负载均衡损失长这个样子? 首先回到负载均衡的设计初衷,是希望每个专家被选到的概率
都接近,那就是 , 而对于$\min \sum_{j=1}^{N} \left( \frac{c_j}{S} \right)^2 \quad \text{s.t.} \quad \sum_{j=1}^{N} \frac{c_j}{S} = 1 \frac{1}{N} L_{\mathrm{aux}} = \sum_{j = 1}^{N} (f_j)^2= \sum_{j = 1}^{N} (\frac{C_j}{K \cdot T})^2 C_j P_j f_j$,变成 $L_{\mathrm{aux}} = \sum_{j = 1}^{N} f_j\cdot C_j $.
评估负载均衡的方式?
看 token 丢弃率,高则说明模型处于不均衡状态;
看模型性能,降低则可能说明模型过于均衡而导致缺少专业化能力。
一些重要参数的权衡

架构发展
Switch Transformer
解决问题:
多数研究者认为,激活的专家数越多,模型性能越优,但这会显著增加每个 token 的计算量。当激活专家数较少时,token 被丢弃的概率增大。例如,当只激活 1 个专家时,每个 token 只有一次选择专家的机会,若该专家容量已满,该 token 就会被丢弃。➡️ 故而激活专家数变化了,专家容量也要考虑好。
方案:Google 提出,仅激活一个专家,并通过容量因子参数灵活控制专家的容量。
**效果:**Switch Transformer 使用更少的激活量来扩展模型参数,将模型扩展到 1.6 万亿参数。
具体细节:
- 专家容量 B 和容量因子 CF 的控制关系:


实验:
实验 1:验证本文模型效果好
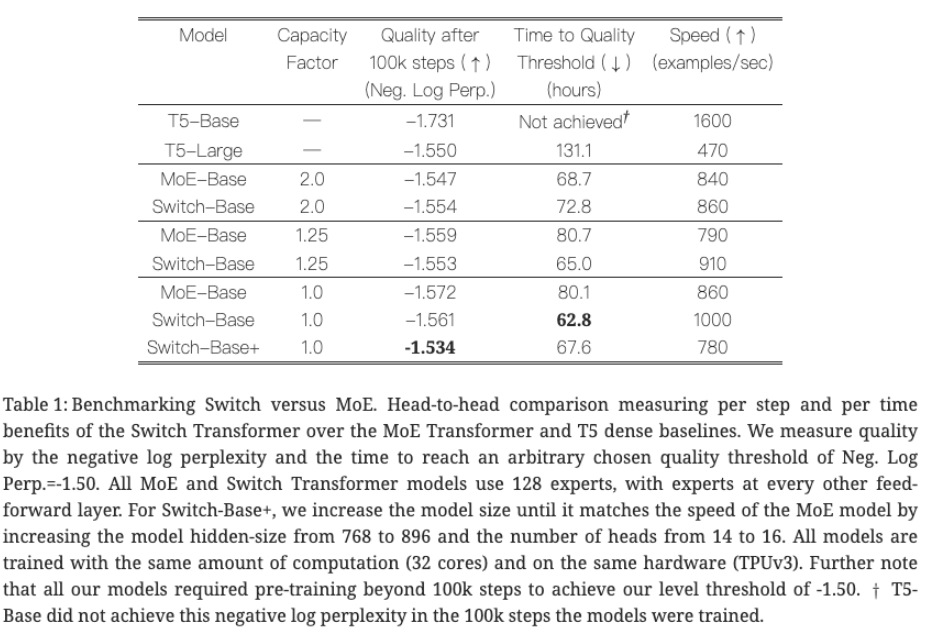 模型配置:
模型配置:
- 基线模型:T5-Base(密集模型)、MoE-Base(top-2 路由,2 专家)。
- Switch Transformer:Switch-Base(128 专家,k=1 路由), Switch-Base+ 是将每个专家参数增大,使得计算速度接近 MoE-Base。
评估指标:
- 负对数困惑度(Neg. Log Perp.):衡量语言模型预训练质量(越低越好)。
- 达到质量阈值的时间(小时):衡量训练速度(越低越好)。
- 速度(examples/sec):每秒处理的样本数(越高越好)。
实验结果分析:
- 对比 Switch-Base 和 MoE-Base:当容量因子相同时,Switch-Base 的训练速度(examples/sec)始终高于 MoE-Base,这是因为激活专家数少则减少通信时间;当用接近的计算量时, Switch-Base+ 比 MoE-Base 好,这是因为 Switch-Base+ 用节约的激活量换取了更大的模型参数。
- 对比 Switch-Base 和 T5-Large:T5-Large 达到困惑度阈值(-1.55)需 131.1 小时,而 Switch-Base(容量因子 = 1.0)仅需 62.8 小时,速度快 2 倍以上。
- 对于 CF 权衡:CF 小,计算速度快,这是因为通信成本降低;CF 大,token 被丢弃概率低,训练会更稳定,故而作者认为 CF=1~1.25 是最好的。
**实验结论:**在相同计算量的前提下,Switch 选择更少的激活量,更大的模型(专家数量和专家大小),提升了模型训练速度和效果。
**方案缺陷:**CF 要精心设置。如果容量因子(CF)设置不当,可能会导致过多的标记被丢弃或过多的标记分配给一个专家。
DeepSpeed-MoE
解决问题:
实验发现,更深层的 MoE 层需要更多专家;同时实验发现固定 1 个专家 +Top-1 与 Top-2 的方式,两者性能相当但训练速度快了 10%。
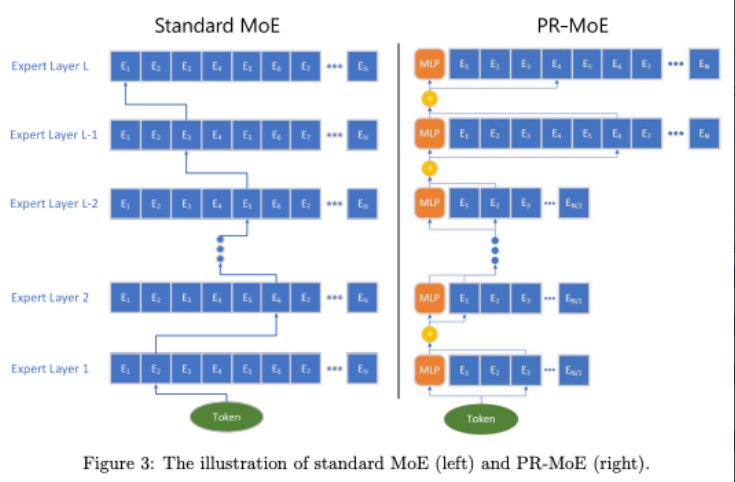
**方案:微软这个工作 **提出 PR-MoE 的结构,1️⃣ 该结构深层结构比低层模型专家数多,2️⃣ 且每个 token 都会都会通过 MLP 模块(共享专家)。
效果:在不影响模型质量的前提下,将模型大小减少 3 倍。
具体细节:
如右图所示,
- 最后两层的专家数是前几层的两倍多;
- 每个 token 都会通过一个固定住的专家(右图中的黄色 MLP,本文是 Top-1 的方式)和一个选择的专家(Top-1),这种模型叫做 Residual-MoE,每一层的表达式为:$y = \mathrm{MLP}^{(l)}(x) + g \cdot Expert^{(l)}(x) $
实验:
实验 1:验证更深层的 MoE 需要更多专家
 实验设置:
实验设置:
- 基于 350M+MoE 模型(12 层 MoE,每层 128 专家),
- First-Half-MoE:前 12 层为 64 个专家,后 12 层为 128 个。
- Second-Half-MoE:前 12 层为 128 个,后 12 层 64 个。
实验结果分析:
First-half MoE 比 second-half MoE 效果好,说明更深层的 MoE 需要更多专家。导致这种现象的原因可能与 CV 中一个广泛研究的结论相同:"浅层(靠近输入)学习通用表示,深层(靠近输出)学习更客观的特定表示"。
实验 2:验证共享专家的效果
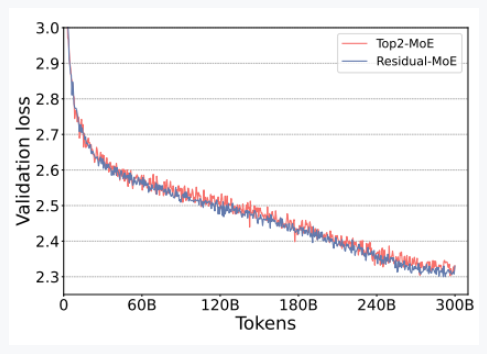 实验设置:
实验设置:
- 基于 350M+MoE 模型(12 层 MoE,每层 128 专家),
- Top2-MoE:Top-2
- Redial-MoE:固定 MLP + Top-1 的动态专家
实验结果分析:
两者损失曲线几乎重合,表明 Residual-MoE 与 Top2-MoE 泛化能力相当。但因通信量减少,Residual-MoE 比 Top2-MoE 快 10% 以上。
导致这种现象的原因可能是专家有冗余的共同能力。
实验 3:验证本文提出的模型效果好
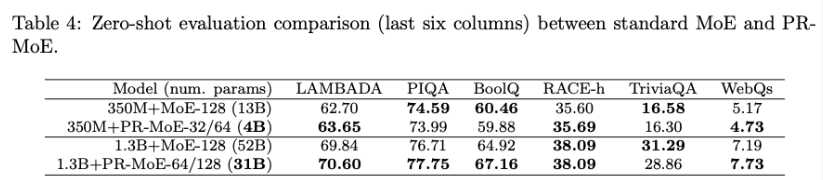
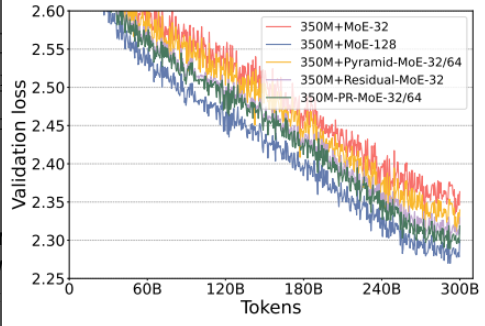
实验设置:
- 350M+PR-MoE-32/64:使用金字塔结构,前 10 层 MoE 层各 32 个专家,后 2 层各 64 个专家,每个专家 350M,总参数 40 亿。
- 1.3B+PR-MoE-64/128:前 10 层 MoE 层各 64 个专家,后 2 层各 128 个专家,每个专家 1.3B,总参数 310 亿。
- 对照组:标准 MoE 模型(350M+MoE-128 和 1.3B+MoE-128),每层均含 128 个专家,参数分别为 130 亿和 520 亿。
- 评估指标:在 6 个零样本任务(LAMBADA、PIQA、BoolQ 等)中对比模型准确率,并观察验证损失曲线。
实验结果分析:
- 表格中看到,在 350M 和 31B 情况下,模型性能相近但是 PR-MoE 参数量仅使用 1/3。
- 在右图中看到,上两个实验得到的两种结构(深层比低层专家多;共享专家)组合起来,比单独使用好,性能接近 MoE-128。
实验结论:
DeepSpeed-MoE 提出的 PR-MoE,通过金字塔结构和共享专家的设置,充分利用了模型参数。
方案缺陷:
不同层不同专家数,会导致并行效率不高。
ST-MoE
解决问题:
在稀疏模型的混合精度训练中,存在因 float32 转换为 bfloat16 带来的精度损失和训练收敛稳定性问题。具体而言,前向与反向传播采用 bfloat16,梯度更新使用 float32,当数值较大时,这种转换易造成明显精度损失,尤其在稀疏模型中因路由器的指数函数运算(softmax 运算)而被放大,影响损失值收敛的稳定性。



DeepSeek-MoE( deepseek v2)
解决问题:

具体细节:
- **细粒度专家分割方法:**以往方法是 N 个专家里选择 k 个,而这个方法是把每个专家划分成更小 m 个更小的专家,然后从 mN 个专家里选择 mk 个。

- **共享专家隔离方法:**除了细粒度专家分割策略外,隔离了
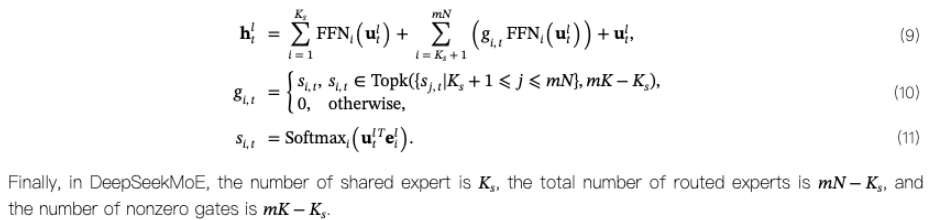
实验:验证提出的细粒度分割,以及共享隔离方案的有效性

图例说明: 横轴表示评估任务:
- HellaSwag:常识推理任务,判断故事的合理结局(准确率)。
- PIQA:物理常识推理任务,解决日常问题(准确率)。
- ARC-easy:科学问答任务(简单版),测试基础科学知识(准确率)。
- ARC-challenge:科学问答任务(挑战版),测试复杂科学推理(准确率)。
- TriviaQA:闭卷问答任务,回答事实性问题(Exact Match 准确率)。
- NaturalQuestions:自然问题问答任务,提取文本答案(Exact Match 准确率)。
纵轴表示归一化性能,即将每个任务的模型性能除以该任务的最佳性能(最大值),范围为 0 到 1,越接近 1,表明模型性能越接近该任务的最优水平。
实验设置:(确保具有相同数量的参数和激活参数)
蓝色:Gshard(基准)
橙色: +1 个共享专家
绿色:1 个共享专家 + (m=2)的细粒度分割
红色:1 个共享专家 + (m=4)的细粒度分割
实验结论: 细粒度分割和共享专家隔离可以提升模型效果
- 细粒度专家分割(m=2**)**
Skywork-MoE
解决问题:
实验发现存在一种情况,当被选中的前 K 个专家和没被选中的专家门控概率差异不大,门控难以区分不同专家。
**方案:**提出 Gating Logit Normalization,即在门控的 softmax 之前添加归一化步骤,然后利用超参数
具体细节:

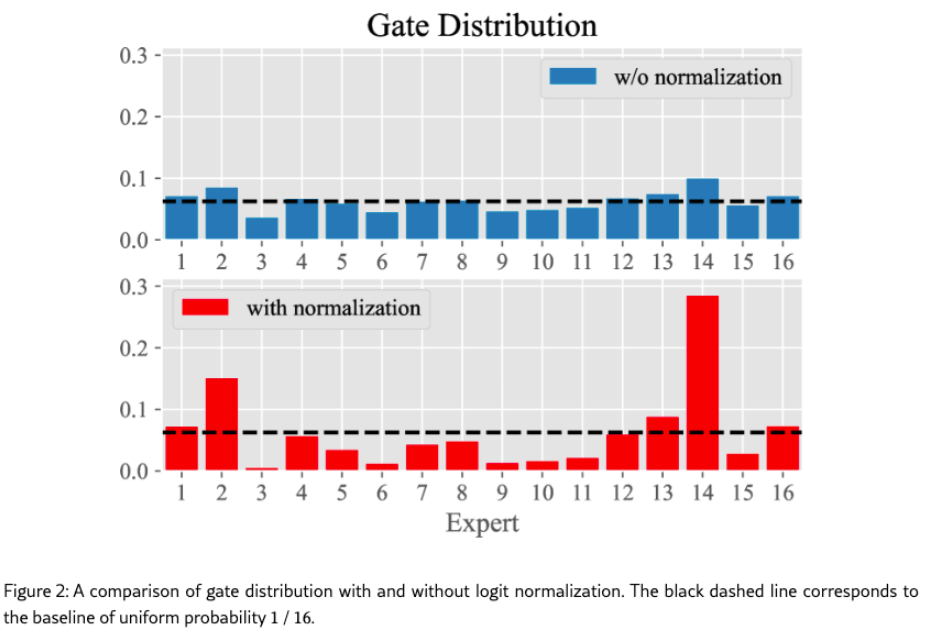
实验:验证 Gating Logit Normalization 方法效果
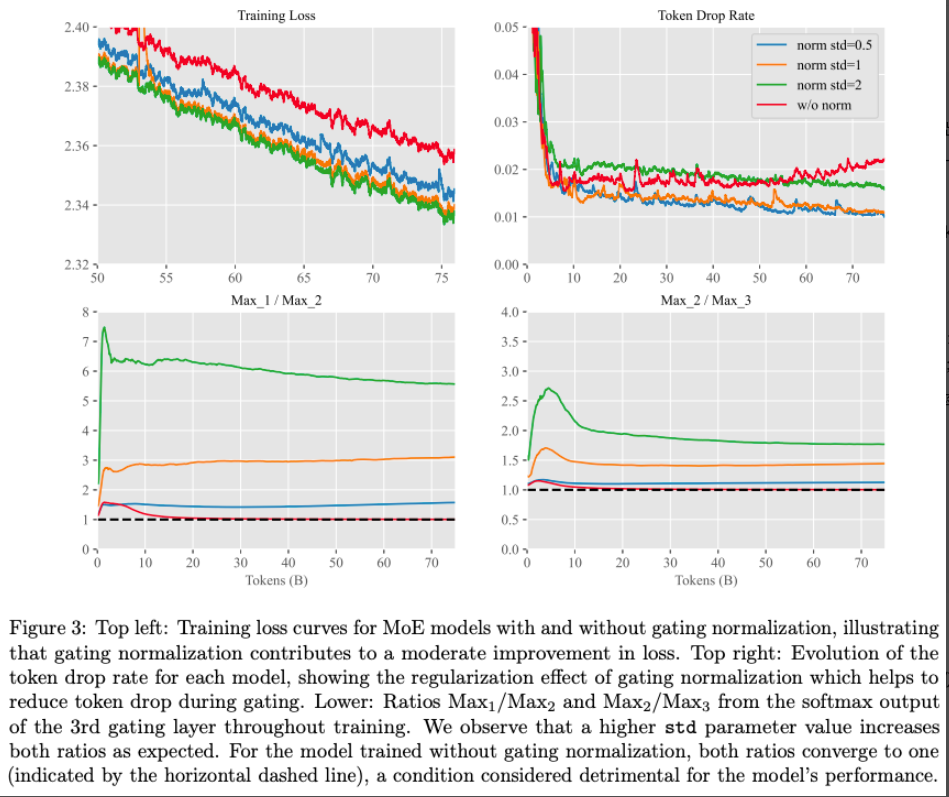


DeepSeek-V3
解决问题:
- 问题 1: DeepSeek-V3 使用了 256 个路由专家(V2 版本 160 个),在这种大维度下,由于 softmax 的计算会使得所有维度总和是 1,使得每个维度的数值小,区分度不高。不利于筛选 TopK。
这个动机 DeepSeek-V3 原文没有说,这个猜想是来自 https://zhuanlan.zhihu.com/p/18565423596
- 问题 2: 辅助损失可以降低负载不平衡问题,但是过大的辅助损失会损害模型性能,为了两者权衡,使用无辅助损失的负载均衡策略。
**方案: **
对于问题 1,DeepSeek-V3 使用 sigmoid 函数替换 softmax,使得亲和分数限制为[0,1],不会随着专家变化的数量增多而变小。
对于问题 2,不使用负载均衡损失辅助项,只修改 Top-K 的选择方式。
具体细节:
- softmax 替换 sigmoid:
Softmax 的归一化会抑制非 Top 专家,Sigmoid 保留所有专家信息.


如何判断专家过载,文章好像说是根据定期检测的统计数据得到的。

实验: 验证无辅助损失策略可以提升专家专业化
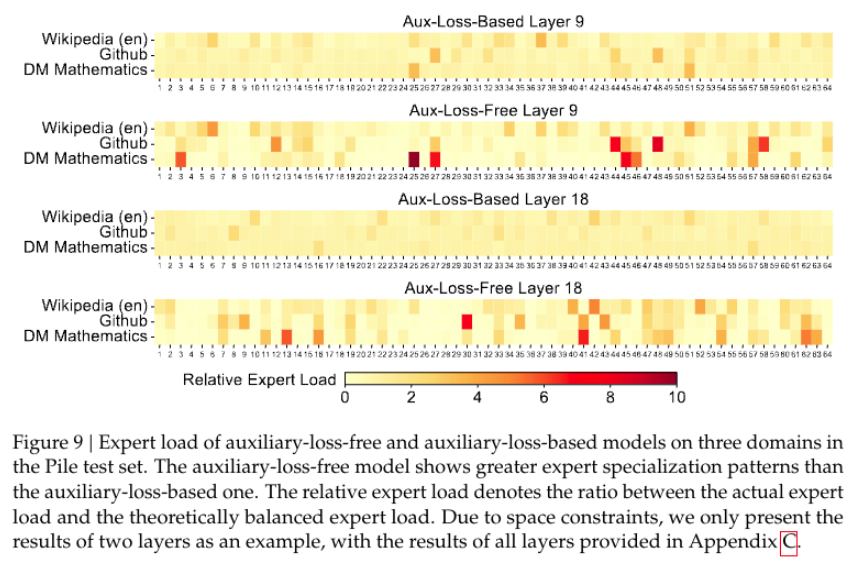 实验设置: Aux-loss-Based,使用普通负载均衡辅助 loss 的方式 Aux-loss-Free,使用本文的方式 Layer 表示第几个专家层
实验设置: Aux-loss-Based,使用普通负载均衡辅助 loss 的方式 Aux-loss-Free,使用本文的方式 Layer 表示第几个专家层
图例说明:
横坐标是 64 个专家
纵坐标是表示三个领域测试数据集(Wikipedia 英文、GitHub 代码、DM Mathematics 数学)
图内颜色块表示每个专家的 相对专家负载率的大小,
- 实际专家负载= 推理完测试数据集后,每个专家激活的总次数。
实验结果分析:
- Aux-loss-Based 导致专家 不同领域都表现出相似的专家分布,说明过分强调平均负载而 没有深入学习领域特征。
- DeepSeek-V3 提出的 Aux-loss-Free 使得不同领域的专家分布更有差异性,说明学习了专家专业化程度更高。
**实验结论:**无辅助损失策略促进专家专业化
负载均衡损失的发展
设备级平衡损失 (DeepSeek-MoE)
解决问题:
当专家分布在多个设备上,负载不平衡会加剧计算瓶颈。
**方案:**DeepSeek-MoE 提出要按不同设备分组, 计算组内专家分布,再合并计算全局 loss。
具体细节:

自适应的辅助损失系数(Skywork-MoE)
解决问题:
Skywork-MoE 发现以下两点:
(1)每个门控层的辅助损失系数不一定要相同
(2)在训练过程中,如果专家负载已经平衡,要降低辅助系数,否则会影响交叉熵预测下一个 token;而当不平衡的时候,表现为大量 token 被丢弃,故而要加强辅助系数。
方案: 根据 token 的丢弃率来调节辅助损失系数
具体细节:

实验:验证方法起作用
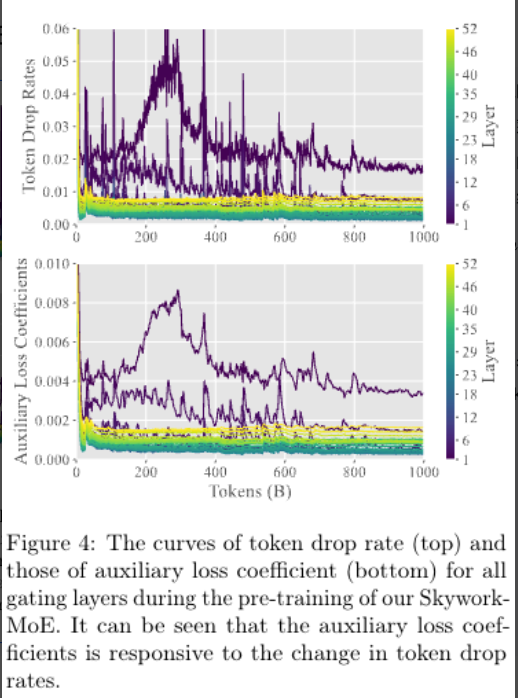 图例说明: 右侧色彩编码代表 52 个门控层,故而图中有 52 条曲线; 两个图的横轴都表示随着训练次数增加的 token 数; 上图的纵轴表示 token 丢弃率,下图的纵轴表示辅助损失系数;
图例说明: 右侧色彩编码代表 52 个门控层,故而图中有 52 条曲线; 两个图的横轴都表示随着训练次数增加的 token 数; 上图的纵轴表示 token 丢弃率,下图的纵轴表示辅助损失系数;
实验结果分析: 随着 token 丢弃率下降,辅助损失系数也响应下降了。
互补序列辅助损失 Complementary Sequence-Wise Auxiliary Loss**(DeepSeek-V3)**
解决问题:
为防止单个序列内出现极端不平衡情况,即一个序列里的多个 token 都集中选择某几个专家。
**方案:**提出要以序列为单位计算 LBL。
具体细节:

基于全局批次的辅助损失 (qwen3 中使用)
解决问题;

具体细节:

新颖的 MoE 框架(偏科研创新)
MoE++
解决问题:
在语言任务中,并非所有的 token 都有相同的预测难度,仅仅是简单的堆积模型参数会导致模型性能次优。
**方案:**对 MoE 中的专家类型做扩展,增加了 3 种类型的专家:(1)Zero 专家:专家输出始终为 0.(2)Copy 专家:专家输出等于专家输入 (3)Const 专家:专家输出包含常数项。同时为了能兼容这些类型,对门控机制做了修改,使得会受到上个门控的残差影响。 同时这样可以减少计算量。
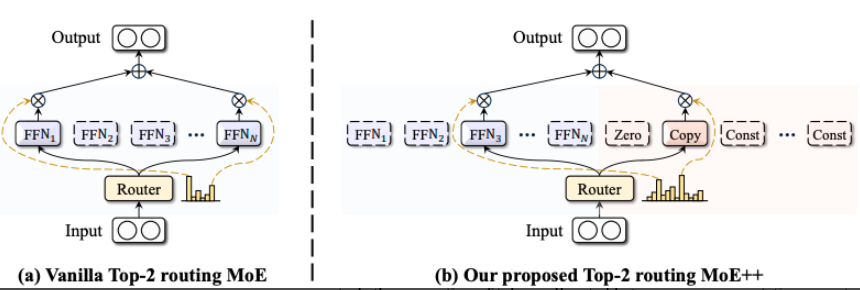
具体方案:


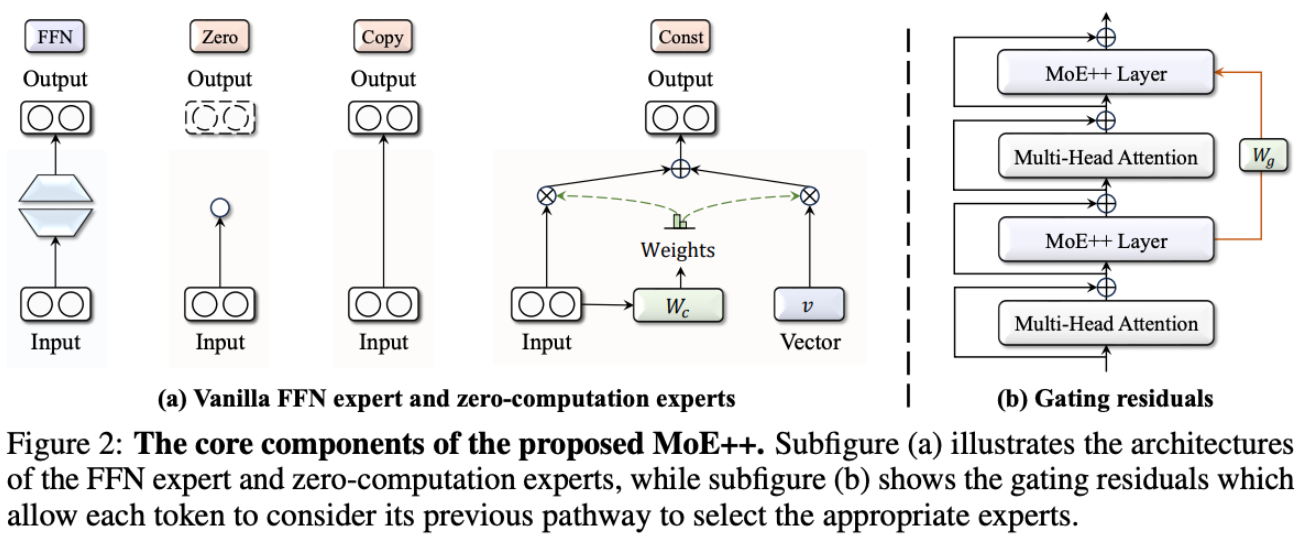
Top-p 动态路由机制
解决问题:
不是所有 token 有相同预测难度,每个 token 不一定需要相同的专家数量,这样会浪费计算资源。
方案:北京大学王选研究所 ➡️ 提出 Top-P 的方式,只要求选择的专家概率值总和高于阈值 p 即可,这样对于简单问题,会选择个数少的专家;对于复杂问题,则会选择更多专家。
具体细节:
路由方式:

动态损失项:
由于 Top-P 的方式会存在一个风险,即会对所有专家分配低的路由概率,从而激活更多专家以获得更好性能,这样违背了 Top-P 框架对效率追求的初衷,故而要约束路由概率是熵小的情况,于是损失函数多加了一项动态损失
熵是用来描述概率的集中情况, 比如今天的天气情况, A 预测: 阴天 32%,晴天 33%,雨天 35%; B 预测: 阴天 70%,晴天 15%,雨天 15%; 则 A 预测要比 B 预测的熵大,因为不确定性更高,所有情况发生概率接近。 在这里希望熵小,表示希望每个 token 选择专家的时候确定性高,路由概率概率高。
关于预训练和 SFT:
该文是一个路由机制的创新,实验都在预训练阶段展开,没有 SFT 微调相关。
实验:
实验 1: 验证可以减少专家激活个数
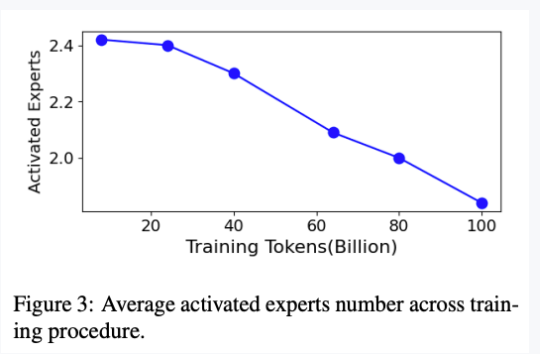 图例说明: 横轴:训练的 tokens 数量随着训练次数而增加 纵轴:平均激活的专家数 实验结果分析: Top-P 架构随着训练进行,激活专家数下降
图例说明: 横轴:训练的 tokens 数量随着训练次数而增加 纵轴:平均激活的专家数 实验结果分析: Top-P 架构随着训练进行,激活专家数下降
附录
MoE 经典论文及团队信息表

其他文章
