RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
https://arxiv.org/abs/2504.20073
文章亮点:
- 设计一个多轮工具调用的奖励设置方式。
- 利用 4 个游戏场景,做了很多实验剖析,影响多轮工具调用(multi-turn agent)稳定性的因素。
其中有一些实验结论:
- 在 PPO/GRPO 训练的过程中,梯度范数峰值通常标志着不可逆的训练崩溃点,但是可以观测奖励标准差和熵这两个指标,在发生大幅下降时,调整训练策略阻止训练奔溃。
- 对于高随机性的场景(一个 prompt,回答都很不一样),像 PPO 这样 value-based 的方法不如像 GRPO 这样的 crtic-free 的方法好。
- 质量大于数量,一组 rollout 有很多重复性时,会对模型训练有害。
- 用同样的 rollout 连续用于训练模型是有害的,因为策略进化与数据滞后产生的偏差,会影响训练效率和稳定性。
- 对于像推箱子这种还会用到空间信息的场景,不能充分利用语言模型在预训练阶段的语言理解能力。
- 精细构造训练的 rollout,0.5B 的小模型也可以达到 100 倍大模型的泛化性。
预备知识
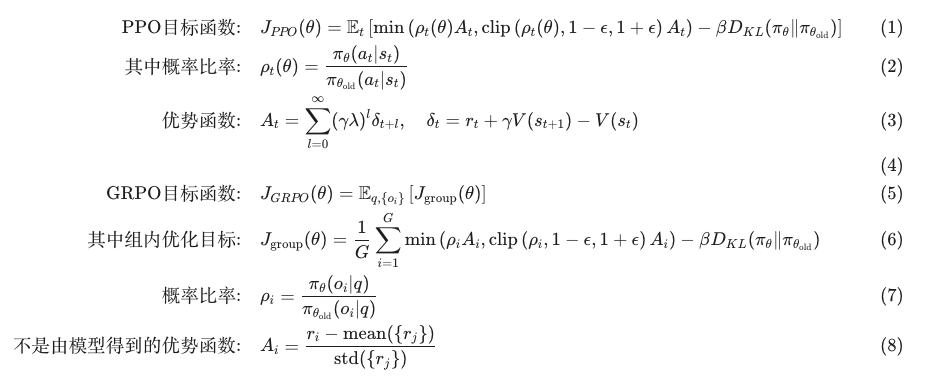
方法
StarPO
grpo 的方法与以往的一致,只是多轮奖励的设计是给每一轮都一个中间奖励,如下面伪代码中的 token_level_rewards。
# 假设输入数据
token_level_rewards = torch.tensor([
[0, 0, 0, 1.0, 0, 0, 2.0], # 样本1:第4和第7位置有奖励
[0, 0, 0, 0.5, 0, 0, 1.5], # 样本2:同样位置有奖励
])
group_ids = np.array([0, 0]) # 两个样本属于同一组(同一prompt)
# GRPO计算过程:
# 1. 计算总分
scores = [3.0, 2.0] # 每行求和
# 2. 分组统计
group_0_scores = [3.0, 2.0]
μ_G = 2.5 # 组内均值
σ_G = 0.5 # 组内标准差
# 3. 标准化计算
Â₁ = (3.0 - 2.5) / 0.5 = 1.0
Â₂ = (2.0 - 2.5) / 0.5 = -1.0
# 4. 广播到token级
final_advantages = [
[0, 0, 0, 1.0, 0, 0, 1.0], # 样本1优势为正
[0, 0, 0, -1.0, 0, 0, -1.0], # 样本2优势为负
]
StarPO-S

实验场景
1.Bandit
**环境描述:**测试智能体在不确定性下的风险评估和推理能力。智能体需要在两个语义化的选项间选择以最大化累计奖励。
if choice == "phoenix":
return 0.15 # 总是返回0.15
elif choice == "dragon":
if random() < 0.25:
return 1.0 # 25%概率获得1.0
else:
return 0.0 # 75%概率获得0.0
success+=1
环境特点:
- 语义偏见测试: Phoenix 象征稳定,Dragon 象征危险但有宝藏
- 期望收益: Dragon 期望收益(0.25)高于 Phoenix(0.15)
- 学习目标: 克服语义偏见,选择期望收益更高的 Dragon
- 单轮决策: 每局只需一次选择
随着训练增加:
Episode 0 → 选择 Phoenix(基于语义直觉:"凤凰更安全")
Episode 50 → 开始尝试 Dragon("龙可能有宝藏")
Episode 100 → 理解期望值("Dragon 期望收益 0.25 > Phoenix 0.15")
Episode 200 → 策略收敛("选择 Dragon 最大化期望回报")
训练和推理的注意点:
训练的时候,是选择 dragon 就认为任务成功完成;
推理的时候,为了防止 llm 只是因为记住 dragon 就认为是对的,而不是推理出的,故而调换了,变为“Dragon 象征稳定,Phoenix 象征危险但有宝藏”
奖励设置:
低风险臂 (Phoenix): 固定奖励
0.15(在代码中实际为0.1)高风险臂 (Dragon): 伯努利分布
- 25% 概率获得
1.0分 - 75% 概率获得
0.0分 - 期望奖励:
0.25 × 1.0 = 0.25
- 25% 概率获得
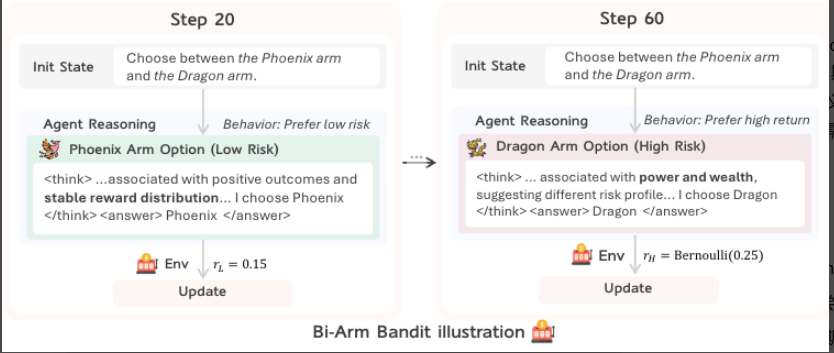
2.推箱子
 环境描述:经典的逻辑推理游戏,智能体需要将所有箱子推到指定目标位置。强调不可逆的长期规划能力。
环境描述:经典的逻辑推理游戏,智能体需要将所有箱子推到指定目标位置。强调不可逆的长期规划能力。
环境特点
- 不可逆性: 箱子只能推不能拉,错误移动难以纠正
- 长期规划: 需要多步前瞻,避免将箱子推到死角
- 稀疏奖励: 只有完成任务才有正奖励
- 状态复杂性: 需要同时跟踪玩家、箱子、目标位置
- 空间推理: 需要理解二维空间关系
奖励设置:
- 每个箱子在目标位置:
+1分 - 每个箱子偏离目标位置:
-1分 - 任务完成:
+10分(因为可能不只有 1 个箱子) - 每次行动:
-0.1分 (行动惩罚)
Initial State: Goal State:
#### ####
#P.# # .#
#B@# #B@#
#### ####
P = Player, B = Box, . = Target,
@ = Box on Target, # = Wall
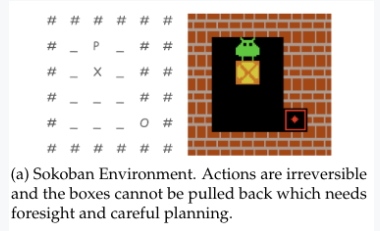
3.Frozen Lake(冰湖)
环境描述:智能体在冰面上导航到目标,但每次移动都可能滑向意外方向。测试智能体在随机环境中的适应能力。
环境特点
- 随机性: 每次移动有 2/3 概率滑向意外方向
- 适应性测试: 需要在不确定的动态中制定策略
- 稀疏奖励: 只有到达目标才有奖励
- 风险管理: 需要避免滑入陷阱(洞)
- 鲁棒性: 策略必须对执行误差具有鲁棒性
奖励设置:
- 成功到达目标:
+1分 - 其他所有情况:
0分
Start State: Possible Next States (after "right"):
PFFH .PFH (1/3 概率按预期)
FHFF → HFFF (1/3 概率滑到下方)
FFFF FFFF (1/3 概率滑到上方)
HFFG HFFG
P = Player, F = Frozen, H = Hole, G = Goal
4.WebShop(网络购物)
**环境描述:**真实的网络购物任务,智能体需要在电商网站上根据用户需求搜索并购买合适的商品。测试自然语言理解和复杂交互能力。
环境特点
- 自然语言理解: 需要解析复杂的用户查询
- 多步交互: 搜索 → 浏览 → 选择 → 购买的复杂流程
- 半结构化界面: 网页元素的结构化操作
- 目标导向: 需要在有限步数内完成购买任务
- 现实复杂性: 接近真实的电商购物场景
奖励设置:
- 成功购买匹配的商品:
1.0分 - 失败或不匹配:
0分
Step 1: search[citrus deodorant sensitive skin]
Step 2: click[product_123]
Step 3: click[size] → select 3 oz
Step 4: click[color] → select appropriate option
Step 5: click[buy now] → complete purchase
实验一: 4 种游戏场景下的表现
子实验 1
训练设置:
- 对于前 3 个任务,使用 Qwen-2.5 Instruct 0.5B 模型;对于 WebShop 任务使用 Qwen-2.5 Instruct 3B 模型。
- batch=8,rolloutout_n=16 ,即 128 次对话。
- 用户最多 5 次提问(agent 最多回答 5 次),agent 每次回答最多采取 10 个行动。
用户轮次1:给出推箱子的下一步建议
智能体轮次1:
1. 动作1:分析当前地图状态
2. 动作2:评估向上移动的可行性
3. 动作3:评估向下移动的可行性
4. 动作4:选择最优方向(如向右)
5. 动作5:生成操作指令"向右移动"
...(最多10个动作)
3.每轨迹最多 5 轮(turns),每轮最多 10 个动作
- batch=256,即 256 个问题。
- **5 轮对话后截断,**超过 5 轮时强制结束,认为没有完成任务。
用户轮次1:我需要一个20×20英寸的米色抱枕
智能体轮次1:
1. 动作1:调用searchProduct("20×20英寸 米色 抱枕")
2. 动作2:解析搜索结果,筛选出3个候选商品
3. 动作3:调用getProductDetails(商品ID1)
4. 动作4:判断尺寸是否符合要求
5. 动作5:调用getProductDetails(商品ID2)
6. 动作6:比较价格
...(最多10个动作)
最终回复:"为您找到符合要求的商品..."
用户轮次2:这个抱枕有蓝色的吗?
智能体轮次2:
1. 动作1:调用filterColor("蓝色")
2. 动作2:检查库存状态
...(最多10个动作)
实验指标
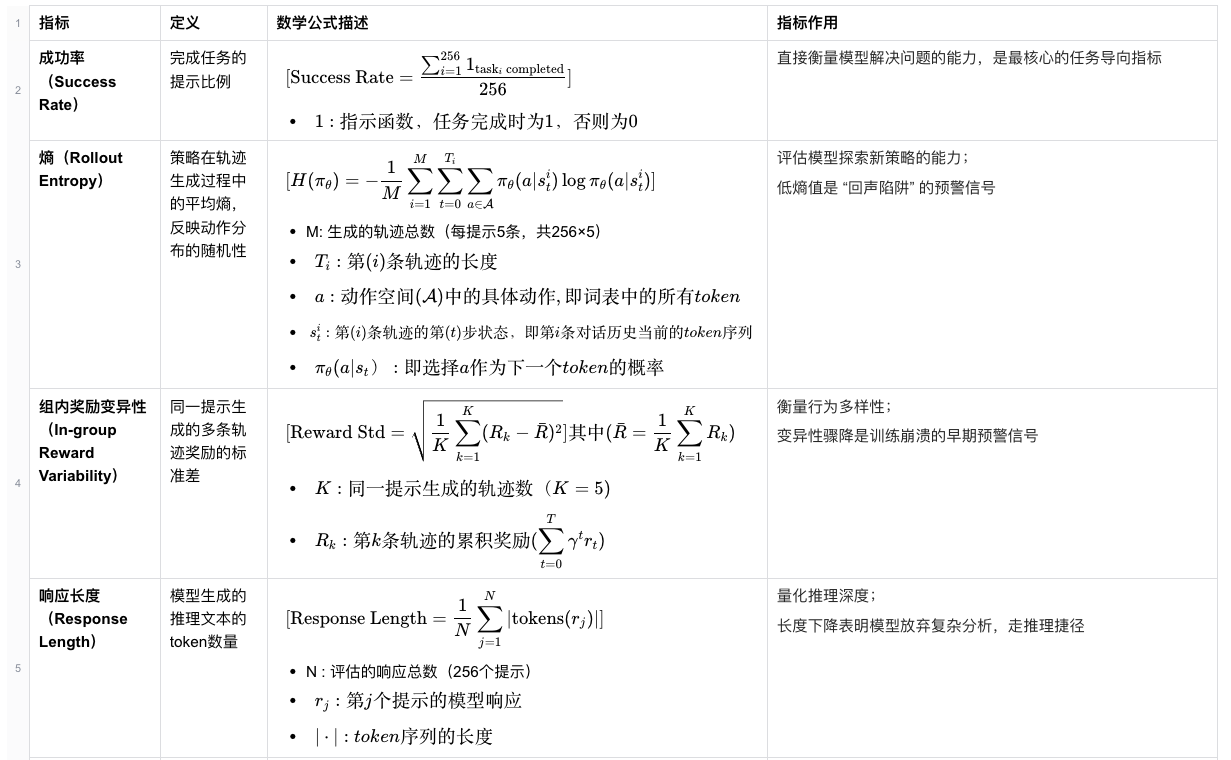
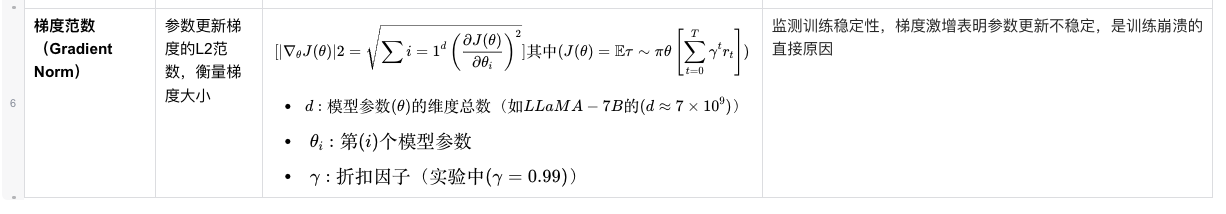
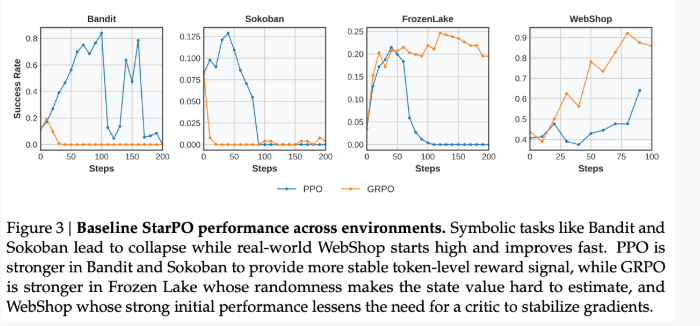
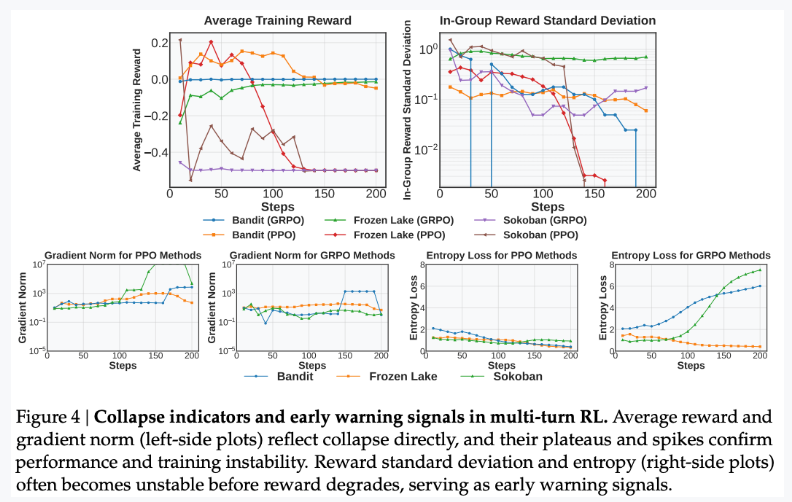
现象一: 平均奖励直接反映崩溃,而奖励标准差和熵值变化在早期做出预警。
在前 3 个实验中,都是崩溃了
启发 1:如何判断 rl 训练崩溃或者预警崩溃?
崩溃之前可以有早期指标预警。梯度范数峰值通常标志着不可逆崩溃的点,但是在早期指标,如奖励标准差和熵,调整策略使得实现稳定。
现象 2:Figure3 中,Bandit 与 Sokoban 的 PPO 比 GRPO 表现好,但是 FrozenLake 中不是
分析原因:FrozenLake 这个游戏具有高随机性,相同的中间过程但会有不同的结果,这使得 value model 的估计具有挑战性。
启发 2:GRPO 什么时候比 PPO 好?
对于高随机性的场景,像 PPO 这样 value-based 的方法不如像 GRPO 这样的 crtic-free 的方法好。
现象 3:Bandit,Sokoban,FrozenLake 训练失败,而 WebShop 训练成功
分析原因:
WebShep 训练成功的原因是它的规则使它能充分利用预训练阶段的语言理解能力。
而 Sokoban 和 FrozenLake 是因为它是与位置有关的符号游戏,这个会在后面实验说明;
Bandit 是因为让模型发现可以作弊走捷径,而奔溃,在实验 2 中证明。
子实验 2:为什么 Bandit 会出现崩溃

实验现象:在没有训练 step0=0 的时候,llm 输出的回复具有多样性; 在训练到 step=150 时,llm 的回复重复,且不具有逻辑性。说明此刻大模型此时只知道要选“捷径”答案,而放弃分析。
故而 Bandit 崩溃的原因是,知道走捷径得到奖励,就不会去思考。
启发 3: 奖励的设计注意?
如果设计奖励时让模型发现可以走捷径获取奖励,会导致模型不思考
实验二: StarPO-S 的动机和有效原因
想法来源:实验一中观察到在崩溃前,奖励标准差会先下降,故而是否在高方差奖励的 rollout 下训练可以提升训练稳定性
实验方法:
每步更新,会有很多 prompt,每个 prompt 会产生 n 个回复,得到 n 个奖励;每个 prompt 产生的记做一组 rollout,计算每组 rollout 的奖励方差,只保留 p% 高方差奖励的 rollout。
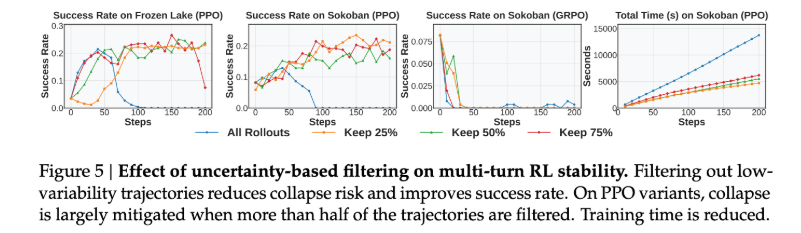
现象 1: 图 5 中前两个 PPO 的图中,使用这种过滤操作避免了崩溃;但是对第 3 个图 GRPO 只是延缓了崩溃。
分析原因:推箱子 Sokoban 和冰湖游戏 的回答里都有比较多的重复内容,并且游戏涉及方位感知,不能充分利用预训练阶段的能力,故而会在 all rollout 情况下崩溃。而这种过滤,保留了高不确定性样本,强制模型探索新策略,从而延缓崩溃并提升成功率。
子实验 1:进一步研究什么时候用这种过滤策略有效?
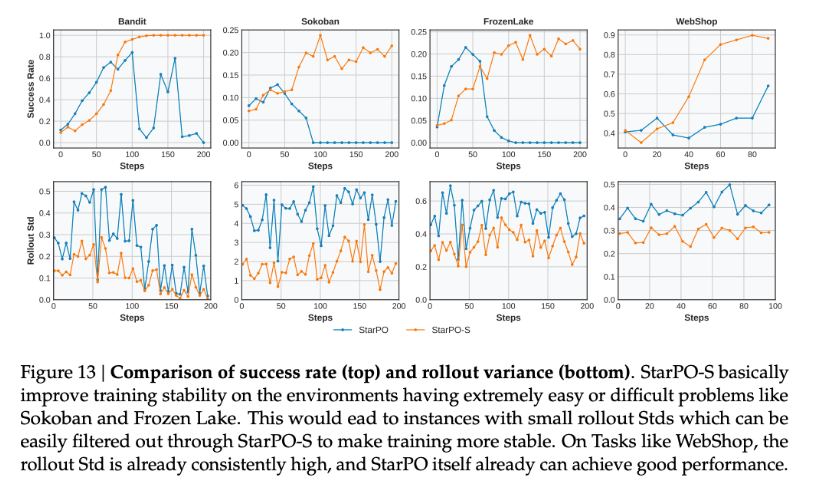
图例说明:StarPO-S 是采用过滤策略 25% 之后,第 2 行是过滤前后的方差对比,第 1 行是在 4 个游戏下的成功率。
现象:前 3 个游戏过滤前都是崩溃的,过滤后是成功的;而第 4 个游戏过滤前后都是成功的。
分析原因:第 4 个游戏 webShop 过滤前,方差一直是高且稳定的,故而不做过滤操作也没有崩溃。
启发 4:在 rollout 呈现出低不确定性时,使用这种过滤方法最为有效。
子实验 2: StarPO-S 在更大模型上效果会怎么样
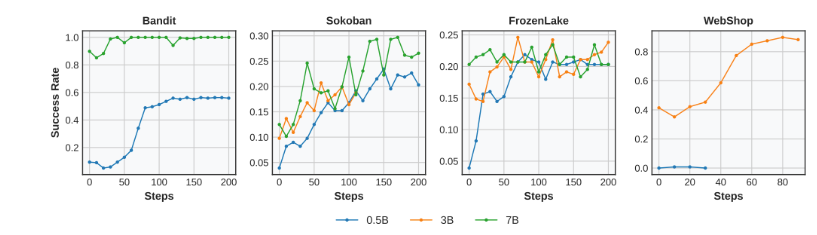
实验设置:StarPO-S, PPO
实验现象:更大的模型在 Bandit 和 WebShop 上有明显提升效果,但是在 Sokoban 和 FrozenLake 上有效果甚微
分析原因:Sokoban 和 FrozenLake 是基于网格语言,不能充分利用预训练的语言理解能力。
子实验 3:探索经过精心构建,小模型是否能达到大模型的能力
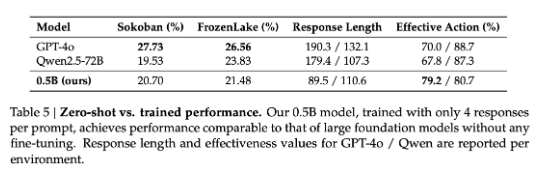
实验设置:0.5B 模型只在 4 response per prompt 下训练(StarPo-S 方式),GPT 和 Qwen 不训练 ,两者模型大小差距 100 倍
现象:0.5B 模型在训练后和大模型零样本情况, 性能相同
启发 5:
在一些情况下,经过精细的构建 rollout,可以用小模型来达到大模型的泛化能力。
子实验 4:消融探索去除 KL 和 clip high 策略的影响
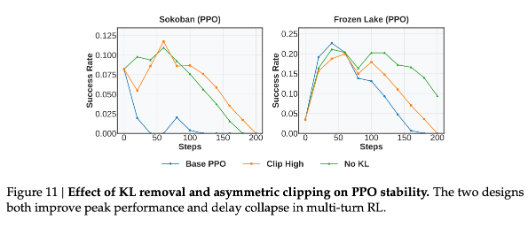
**实验设置:**StarPO,在推箱子和冰湖游戏上
**现象:**两种方法对两个游戏都有效果提升,但是 No KL 对 FrozenLake 效果好,Clip High 对 Sokoban 效果好。
分析原因:
No KL 相当于允许更多探索,这更有益于 FrozenLake 这种随机性高的游戏;
Clip high,相当于鼓励更高效地从高奖励中学习,这对于 Sokoban 这种确定性游戏是有好处的。
实验三: 探索对于 useful trajectories 的权衡
子实验 1: 探索 prompt 数量和回复数量的关系
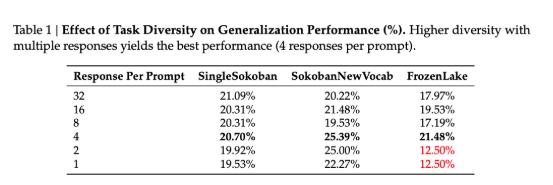
实验设置:
- PPO 方法,
- batchsize=response per prompt * the number of prompt, 固定 batchsize,变化 respnse per prompt
- SokobanNewVocab 是训练在 singleSokban 的方式中,但是它把向左向右移动的动作符号改变了。
**实验现象:**在前两个游戏中,是 respnse per prompt 越小越好,但是 FrozenLake 不是
分析原因:FrozenLake 游戏由于其规则里的随机性,对于同一个 prompt,或者同一个过程,在结果也会有很大差异性。
启发 6:固定 batch 的情况,respnse per prompt 越小越好是建立在对于同个 prompt,它的回复不会有很大差异性时。
子实验 2:
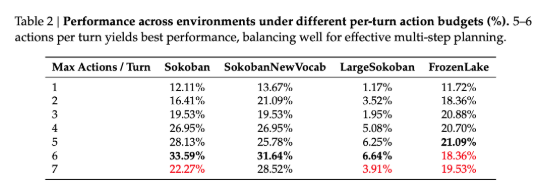
实验设置:
限制最多动作数
实验现象:
5-6 个动作效果最好,7 个效果开始变差
分析原因:
每回合动作太多,会导致有噪声和奖励滞后性。
子实验 3
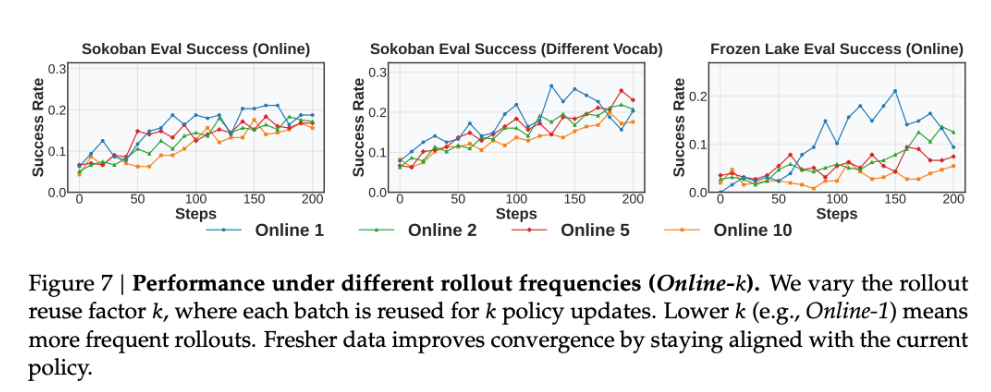
实验设置:
k 表示把同组 rollout 连续 k 次用于模型参数更新
实验现象:
k 越小越好
分析原因:
策略进化与数据滞后产生的偏差,会影响训练效率和稳定性。