DPO 公式推导
DPO 公式
数据集
注意点:
由于是句子级别的,x 和 y 都是由很多 token 构成的,
DPO 的奖励分数是什么
就是
DPO 公式怎么来的
1.DPO 是为了简化 PPO 而产生
PPO 来源于 policy-based 的强化学习,它希望寻找策略使得策略奖励最大(另一类 vlue-based,是希望行动奖励最大),同时为了稳定它希望当前新策略和旧策略不能差异太大。
其中:
然而,PPO 这样首先得训一个奖励模型,这样太麻烦。DPO 就希望绕过这个。
于是 DPO 是对 PPO 的公式展开。
2.对 PPO 公式展开,利用策略分布

定义一个新的概率分布
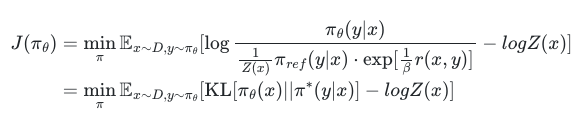
要让
那么从这个公式就可以反推出奖励模型的表达式:
3.引入 Bradley-Terry 模型,通过偏好对比方式化解了直接最大化。
首先看 Bradley-Terry 模型定义:

把要奖励最大,利用 Bradley-Terry 化解为了好的回答比坏的回答胜出的概率更大。
即
化简后就是
故而 DPO 的损失函数为:
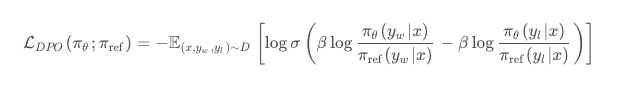
其他问题:
- 为什么 DPO 训练会出现正样本 reward 也会降低的现象
参考博客
DPO 公式推导 把推导逻辑写清楚了
(DPO) Bradley-Terry 模型概念-CSDN 博客 讲 Bradley-Terry 概念